Syllabus: GS3/ Science and Technology
Context
- Bengaluru-based startup Sarvam AI unveiled two indigenous Large Language Models (LLMs), underscoring India’s push for sovereign, multilingual, and compute-efficient AI amid global competition.
Large Language Models (LLMs)
- A large language model (LLM) is a type of artificial intelligence (AI) algorithm that uses deep learning techniques and massively large data sets to understand, summarize, generate and predict new content.
- Deep learning involves the probabilistic analysis of unstructured data, which eventually enables the deep learning model to recognize distinctions between pieces of content without human intervention.
- It helps to understand how characters, words, and sentences function together.
Indigenous LLM Ecosystem in India
- Sarvam AI Models: Focus on efficiency, accuracy, and Indian language capabilities. Intended to be open-source, though broader public scrutiny is ongoing.
- BharatGen, incubated at IIT Bombay, trained a multilingual 17-billion-parameter model for sectors like education and healthcare.
- Gnani.ai launched compact speech and text-to-speech models.
How LLMs Are Trained?
- GPU Clusters: LLM training requires massive computational power using clusters of Graphics Processing Units (GPUs). Thousands of GPUs operate simultaneously for weeks or months.
- Data as the Core Input: Training relies on enormous datasets, often scraped from the Internet.
- Model Parameters: Parameters represent the internal weights through which models learn patterns. Sarvam AI trained models with 35 billion and 105 billion parameters.
- Larger parameter counts improve capability but require more computation.
Key Training Methodologies Used
- Data Curation: It focuses on collecting high-quality datasets in Indian languages.
- It includes government documents, literature, media, and synthetic data generation.
- It is critical for improving performance beyond English-centric AI systems.
- Pre-Training: The models learn general language patterns by predicting the next token in large unlabelled datasets.
- This stage builds foundational reasoning and grammar capabilities.
- Fine-Tuning: Models are adapted for specific tasks using curated datasets.
- Tools such as Hugging Face and LangChain support instruction tuning, classification, and domain adaptation.
- Alignment/RLHF (Reinforcement Learning from Human Feedback): Human raters rank model outputs to teach it to be safer, more accurate, and better aligned with human intent, discouraging harmful or biased responses.
Challenges in Training LLMs in India
- Limited Indian Language Data: Scarcity of high-quality datasets in Indian languages reduces model performance.
- Many systems rely on translation into English before processing, increasing token usage and latency. Suboptimal native performance affects adoption among non-English users.
- High Capital Requirements: Training frontier models demands substantial financial investment. Startups often lack immediate commercial returns to justify such costs.
- Infrastructure Constraints: Access to high-end computing facilities remains limited without government support.
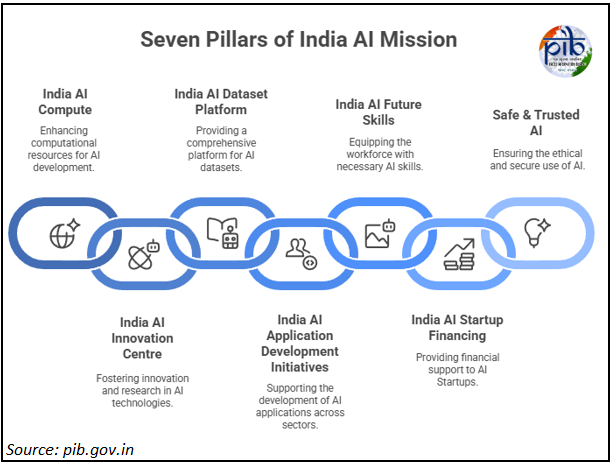
IndiaAI Mission
- The IndiaAI Mission is the flagship initiative to build a comprehensive, sovereign AI ecosystem for India.
- It focuses on developing high-performance computer infrastructure, indigenous foundational models, and safe, ethical AI, under the vision of “Making AI in India and Making AI Work for India”.
- India has achieved 38,000 GPUs, providing affordable access to world-class AI resources.
- A GPU or Graphics Processing Unit is a powerful computer chip that helps machines think faster, process images, run AI programs, and handle complex tasks more efficiently than a regular processor.
Source: TH
Previous article
Energy Imbalance and the Changing Dynamics of El Niño
Next article
Blockchain Based Digital Governance